
Traduzido de: Essentials of Machine Learning Algorithms (with Python and R Codes)
Autor: Sunil Ray
Introdução
Os robôs e os carros de auto condução do Google têm gerado grande interesse por parte da mídia, mas o verdadeiro futuro da empresa está na tecnologia de aprendizado de máquina que permite aos computadores ficarem mais espertos e mais pessoais.
– Eric Schmidt (Google Chairman)
Provavelmente estejamos vivendo o período mais marcante da história humana. O período em que a computação mudou dos grandes mainframes para a computação de PCs em nuvem. No entanto, o que definirá a mudança não é o que aconteceu, mas o que ainda está por vir.
O que torna este período excitante para alguém como eu é a democratização das ferramentas e técnicas que acompanharam o aumento na computação. Hoje, como um Cientista de Dados, eu posso montar máquinas que trituram dados com algoritmos complexos por apenas alguns dólares por hora. Mas, chegar aqui não foi fácil! Eu também tive meus dias e noites sombrios.
Quem pode se beneficiar mais deste guia?
Talvez este seja o Guia mais valioso que eu já criei.
A ideia por trás deste guia é simplificar a jornada dos aspirantes a Data Scientists e entusiastas de machine learning pelo mundo. Por meio dele, irei habilitá-lo a trabalhar com problemas de machine learning e proporcionar ganhos de experiência. Irei proporcionar um alto nível de entendimento sobre vários algoritmos de machine learning com códigos R e Python para rodá-los. E isso pode ser o suficiente para por a mão na massa.

Eu deliberadamente evitarei as estatísticas por trás das técnicas, já que não se tem que entendê-las aqui. Assim, se você procura entender estatisticamente estes algoritmos, procure em outro lugar. Mas se o que você quer é se equipar para construção de projetos de machine learning, você ficará surpreso.
Em termos gerais, existem 3 tipos de algoritmos de Machine Learning..
- Aprendizagem Supervisionada
Como funciona: Estes algoritmos consistem em variáveis alvo ou de saída (variáveis dependentes) que são previstas por um grupo de variáveis predecessoras (variáveis independentes). Usando este grupo de variáveis, nós geramos uma função que mapeia entradas para saídas desejáveis. O processo de treinamento continua até o modelo atingir um determinado nível de precisão desejável nos dados de teste. Exemplos de aprendizagem supervisionada são: Regressão, Árvore de Decisão, Floresta Aleatória, KNN, Regressão Logística, etc.
2. Aprendizagem Não Supervisionada
Como Funciona: nestes algoritmos, nós não temos variáveis alvo ou variáveis de saída para serem estimadas. São feitos agrupamentos de população em diferentes grupos, amplamente utilizados para segmentar os clientes para intervenções específicas. Exemplos de Aprendizagem Não Supervisionadas são: Algoritmos Apriori e aproximação de médias.
3. Aprendizagem por Reforço
Como funciona: estes algorítmos são utilizados para que a máquina seja treinada para decisões específicas. Funciona assim: a máquina é exposta a um ambiente onde ela se treina continuamente usando tentativa e erro. A máquina aprende a partir das experiências passadas e tenta capturar o melhor conhecimento possível para tomar decisões de negócios precisas. Exemplos de aprendizado por reforço: Processo de decisão Markov.
Lista de Algoritmos de Machine Learning Comuns
Esta é uma lista dos algoritmos mais comumente utilizados. Eles podem ser utilizados para quase todos os problemas com dados:
- Regressão Linear
- Regressão Logística
- Árvore de Decisão
- MVS
- Naive Bayes
- KNN
- K-Means (aproximação de médias)
- Floresta Aleatória
- Algoritmo de Redução de Dimensionalidade
- Gradient Boost e Adaboost
1. Regressão Linear
É utilizada para estimar valores reais (custo de residências, número de chamadas, vendas totais, etc) baseado em variáveis contínuas.
Aqui, estabelecemos uma relação entre variáveis dependentes e independentes ajustando a melhor linha. Esta linha de melhor ajustamento é conhecida como linha de regressão e representado por uma equação linear Y = a * x + b.
A melhor maneira de compreender regressão linear é reviver uma experiência de infância. Digamos que você peça a uma criança do quinto ano para ela organizar as pessoas de sua classe por ordem de peso crescente, sem perguntar a elas seu peso. O que ela iria fazer? Ela iria olhar (análise visual) a altura e largura das pessoas e ordená-las combinando estes parâmetros visuais. Isto é uma regressão visual na vida real! A criança realmente estima que a altura e a largura seriam correlacionadas ao peso por relação, o que se parece com a equação abaixo.
Nesta equação:
- Y – Variável Dependente
- a – Declive
- X – Variável independente
- b – Intercepção
Os coeficientes a e b são derivados baseados na minimização da soma dos quadrados da diferença da distância entre os pontos da regressão linear.
Veja o exemplo abaixo. Aqui nós identificamos a melhor linha de ajustamento tendo a equação linear y = 0.2811x + 13,9. Agora, usando esta equação, podemos encontrar o peso, sabendo a altura de uma pessoa.
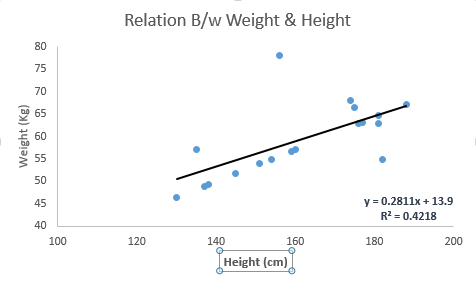
Regressões lineares são fundamentalmente de dois tipos: Regressão Linear Simples e Regressão Linear Múltipla. Regressão Linear Simples é caracterizada por uma variável independente e regressão linear múltipla (como o nome sugere) é caracterizada por múltiplas variáveis independentes e procurando a melhor linha de ajuste, você pode também encontrar uma regressão polinomial ou curvilínea e estes são conhecidos como regressão polinomial ou curvilínea.
Código Python
#Importa a biblioteca #Importa outras bibliotecas como pandas, numpy... from sklearn import linear_model #Carrega os dados de Treino e de Teste #Identifica as variáveis de funcionalidade e de resposta e que valores devem ser numéricos e matrizes numpy x_train=input_variables_values_training_datasets y_train=target_variables_values_training_datasets x_test=input_variables_values_test_datasets #Crie o objeto de regressão logística linear = linear_model.LinearRegression() #Treina o modelo usando os dados de treino e confere o score linear.fit(x_train, y_train) linear.score(x_train, y_train) #Coeficiente da equação e intercepto print('Coefficient: \n', linear.coef_) print('Intercept: \n', linear.intercept_) #Prevê o resultado predicted = linear.predict(x_test)
Código R
#Carrega os dados de Treino e de Teste #Identifica as variáveis de funcionalidade e de resposta e que valores devem ser numéricos e matrizes numpy x_train <- input_variables_values_training_datasets y_train <- target_variables_values_training_datasets x_test <- input_variables_values_test_datasets x <- cbind(x_train,y_train) #Treina o modelo usando os dados de treino e confere o score linear <- lm(y_train ~ ., data = x) summary(linear) #Prevê o resultado predicted = predict(linear,x_test)
2. Regressão Logística
Não se confunda com o nome! Trata-se de uma classificação, não de um algoritmo de regressão. Ela é usada para estimar valores discretos (valores binários como 0/1, sim/não, verdadeiro/falso) baseado em um grupo de variáveis independentes. Em palavras simples, ela prevê a probabilidade da ocorrência de um evento, ajustando os dados a uma função logística. Por isso, também é conhecida como regressão logística. Como prevê a probabilidade, seus valores de saída são algo esperado entre 0 e 1.
Vamos novamente tentar entender a partir de um exemplo simples.
Digamos que um amigo lhe dê um enigma para ser resolvido. Existem somente dois cenários possíveis: – ou você o resolve ou não. Agora, imagine que você tenha um amplo grupo de enigmas para resolver para entender em quais assuntos você é bom. O resultado deste estudo seria algo como – Se é dado a você um problema de trigonometria de grau dez, você tem 70% de probabilidade de resolvê-lo. Por outro lado, se é questão de história de grau cinco, a probabilidade de obter uma resposta é de apenas 30%. Isto é o que Regressão Logística fornece.
Vindo para a matemática, as chances do resultado são modeladas como uma combinação linear das variáveis de previsão.
odds = p/ (1-p) = probabilidade do evento ocorrer / probabilidade do evento não ocorrer ln(odds) = ln(p/(1-p)) logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
Acima, p é a probabilidade de estar presente a característica desejada. Ela escolhe os parâmetros que maximizam a probabilidade de observar os valores das amostras em vez de minimizar a soma dos quadrados dos erros (como numa regressão ordinária).
Agora, você pode se perguntar, por que tomar um log? Por uma questão de simplicidade, vamos apenas dizer que este é uma das melhores formas matemáticas para replicar uma função de etapas. Eu poderia ir em mais detalhes, mas isso não está no propósito deste artigo.

Código Python
#Importa a biblioteca from sklearn.linear_model import LogisticRegression #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria o objeto de regressão logística model = LogisticRegression() #Treina o modelo usando os dados de treino e confere o score model.fit(X, y) model.score(X, y) #Coeficiente da equação e intercepto print('Coefficient: \n', model.coef_) print('Intercept: \n', model.intercept_) #Prevê o resultado predicted= model.predict(x_test)
Código R
x <- cbind(x_train, y_train) #Treina o modelo usando os dados de treino e confere o score logistic <- glm(y_train ~ ., data = x,family='binomial') summary(logistic) #Prevê o resultado predicted= predict(logistic,x_test)
Além disso..
Há muitos passos diferentes que poderiam ser tentados a fim de melhorar o modelo:
- os termos de interação
- remoção de recursos
- técnicas de regularização
- usando um modelo não-linear
3. Árvore de Decisão
Este é um de meus algoritmos favoritos e eu o uso frequentemente. É um tipo de algoritmo de aprendizado supervisionado mais usado para problemas de classificação. Surpreendentemente, ele funciona tanto para variáveis dependentes categóricas quanto contínuas. Nestes algoritmos, nós dividimos a população em dois ou mais grupos homogêneos. Isso é feito baseado nos atributos ou variáveis independentes mais significantes para tornar os grupos o mais distintos possível. Para mais detalhe você pode ler: Decision Tree Simplified.

Na imagem acima, pode-se ver que a população é classificada em dois grupos diferentes baseado em múltiplos atributos, para identificar se eles irão Jogar (PLAY) ou Não Jogar (DON’T PLAY). Para dividir a população em grupos diferentes e heterogêneos, são usadas várias técnicas como Gini, Ganho de informação, Qui-Quadrado e entropia.
A melhor maneira de entender como funciona a árvore de decisão é jogar Jezzball – um jogo clássico da Microsoft (imagens abaixo). Essencialmente temos um quarto com paredes móveis e temos que criar paredes de maneira a maximizar a área sem a presença das bolas.

Então, toda a vez que se divide a sala com a parede, tenta-se criar duas populações diferentes dentro de um mesmo quarto. Árvore de decisão trabalha de maneira muito semelhante, dividindo a população na maior quantidade de grupos diferentes possível.
Mais: Simplified Version of Decision Tree Algorithms
Código Python
#Importa a biblioteca #Importa outras bibliotecas como pandas, numpy... from sklearn import tree #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria objeto tree model = tree.DecisionTreeClassifier(criterion='gini') #Para classificação, aqui você pode mudar o algoritimo como gini ou entropy (ganho de informação). O default é gini # model = tree.DecisionTreeRegressor() for regression #Treina o modelo usando os dados de treino e confere o score model.fit(X, y) model.score(X, y) #Prevê o resultado predicted= model.predict(x_test)
Código R
library(rpart) x <- cbind(x_train,y_train) #Expande a árvore fit <- rpart(y_train ~ ., data = x,method="class") summary(fit) #Prevê o resultado predicted= predict(fit,x_test)
4. VMS (Máquina de Vetor de Suporte)
É um método de classificação. Neste algoritmo, cada dado é plotado como um ponto em um espaço n-dimensional (onde n é o número de características que se tem) com o valor de cada característica sendo o valor de uma coordenada particular.
Por exemplo, se existem somente duas características como peso e comprimento do cabelo de um indivíduo, nós primeiro plotamos estas duas características no espaço onde cada ponto tem duas coordenadas (estas coordenadas são chamadas Vetores de Suporte)

Agora, vamos encontrar uma linha que divida os dados em dois grupos diferentes de dados classificados. A linha ficará no ponto mais próximo em que as distâncias de cada ponto nos dois grupos ficará a maior possível.

No exemplo acima, a linha que divide os dados em dois grupos classificados é a linha preta, pois os dois pontos mais próximos dela são os mais distantes, fora da linha. Este é nosso classificador. Então, dependendo de que lado da linha os dados de testes são colocados, esta será a classe em que poderão ser classificados os novos dados.
More: Simplified Version of Support Vector Machine
Pense neste algoritmo como se estivesse jogando JezzBall em um espaço n-dimensional. Os ajustes no jogo são:
- Você pode desenhar linhas / planos em qualquer ângulo (em vez de apenas horizontal ou vertical como no jogo clássico)
- O objetivo do jogo é segregar bolas de cores diferentes em diferentes salas.
- E as bolas não estão se movendo.
Código Python
#Importa a biblioteca from sklearn import svm #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria objeto de classificação SVM model = svm.svc() #Há várias opções associadas a isso, é simples para classificação. Veja link para mais detalhes. #Treina o modelo usando os dados de treino e confere o score model.fit(X, y) model.score(X, y) #Prevê o resultado predicted= model.predict(x_test)
Código R
library(e1071) x <- cbind(x_train,y_train) #Modelo de acerto fit <-svm(y_train ~ ., data = x) summary(fit) #Prevê o resultado predicted= predict(fit,x_test)
5. Naive Bayes
É uma técnica de classificação baseada no teorema de Bayes que assume a independência entre preditores. Em termos simples, um classificador em Naive Bayes assume que a presença de uma característica particular em uma classe não é relacionada com a presença de nenhuma outra característica. Por exemplo, uma fruta pode ser considerada uma maçã se ela for vermelha, redonda e tenha 3 polegadas de diâmetro. Mesmo que essas características dependam umas das outras ou da existência de outras características, um classificador Naive Bayes iria considerar que todas essas características contribuem de forma independente para a probabilidade de que esta fruta seja uma maçã.
Modelo Naive Bayesiano é fácil de construir e particularmente útil para grandes conjuntos de dados. Além da simplicidade, Naive Bayes é conhecido por superar métodos de classificação altamente sofisticados.
Teorema de Bayes fornece uma forma de calcular a probabilidade posterior P (C | X) a partir de P (C), P (x) e P (X | c). Veja a equação abaixo:

Aqui,
- P (c | x) é a probabilidade posterior da classe (target) dada preditor (atributo).
- P (c) é a probabilidade a priori de classe.
- P (x | c) é a probabilidade que representa a probabilidade de preditor dada a classe.
- P (x) é a probabilidade a priori de preditor.
Exemplo: Vamos usar um exemplo. Abaixo eu tenho um conjunto de dados de treinamento de tempo e a variável target correspondente ‘Play’. Agora, precisamos classificar se os jogadores vão jogar ou não com base na condição meteorológica. Vamos seguir os passos abaixo para realizar a operação.
Passo 1: Converter o conjunto de dados para a tabela de frequência.
Passo 2: Criar tabela de Probabilidade de encontrar as probabilidades como probabilidade Nublado = 0,29 e probabilidade de jogar é 0,64.

Passo 3: Agora, use a equação Bayesiana Naive para calcular a probabilidade posterior para cada classe. A classe com maior probabilidade posterior é o resultado de previsão.
Problema: Os jogadores irão jogar se o tempo está ensolarado, é esta afirmação está correta?
Podemos resolver isso usando o método acima discutido, então P (Sim |Sunny) = P (Sunny | Sim) * P (Sim) / P (ensolarado)
Aqui temos P (Sunny | Sim) = 3/9 = 0,33, P (Sunny) = 5/14 = 0,36, P (Sim) = 9/14 = 0,64
Agora, P (Sim |Sunny) = 0,33 * 0,64 / 0,36 = 0,60, que tem maior probabilidade.
Naive Bayes usa um método similar para prever a probabilidade de classe diferente com base em vários atributos. Este algoritmo é usado principalmente em classificação de texto e com os problemas que têm múltiplas classes.
Código Python
#Importa a biblioteca from sklearn.naive_bayes import GaussianNB #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria objeto de classificação SVM model = GaussianNB() #Há outra distribuição para classes multinomiais como a Bernoulli Naive Bayes, veja link #Treina o modelo usando os dados de treino e confere o score model.fit(X, y) #Prevê o resultado predicted= model.predict(x_test)
Código R
library(e1071) x <- cbind(x_train,y_train) #Modelo de acerto fit <-naiveBayes(y_train ~ ., data = x) summary(fit) #Prevê o resultado predicted= predict(fit,x_test)
6. KNN (K- Nearest Neighbors)
Pode ser usado para ambos os problemas de classificação e regressão. No entanto, é mais amplamente utilizado em problemas de classificação na indústria. K nearest neighbors é um algoritmo simples que armazena todos os casos disponíveis e classifica novos casos por maioria de votos de seus vizinhos k. O caso que está sendo atribuído à classe é mais comum entre os seus K vizinhos mais próximos medidos por uma função de distância.
Estas funções de distância podem ser Euclidiana, Manhattan, Minkowski e distância de Hamming. As primeiras três funções são usadas para a função contínua e a quarta (Hamming) para variáveis categóricas. Se K = 1, então o caso é simplesmente atribuído à classe de seu vizinho mais próximo. Às vezes, escolher o K acaba por se tornar um desafio durante a execução de modelagem KNN.
Mais: Introduction to k-nearest neighbors : Simplified.

KNN pode ser facilmente mapeada para nossas vidas reais. Se você quiser saber mais sobre uma pessoa de quem você não tem nenhuma informação, você pôde saber mais sobre seus amigos próximos e os círculos em que ela se move e ganhar acesso a suas informações!
Coisas a considerar antes de selecionar KNN:
- KNN é computacionalmente caro
- As variáveis devem ser normalizadas. Se não, as variáveis mais elevadas podem enviesa-lo
- Funciona mais em fase de pré-processamento antes de ir para KNN, como outlier e remoção de ruído
Código Python
#Importa a biblioteca from sklearn.neighbors import KNeighborsClassifier #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria modelo de objeto de classificação KNeighbors KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5 #Treina o modelo usando os dados de treino e confere o score model.fit(X, y) #Prevê o resultado predicted= model.predict(x_test)
Código R
library(knn) x <- cbind(x_train,y_train) #Modelo de acerto fit <-knn(y_train ~ ., data = x,k=5) summary(fit) #Prevê o resultado predicted= predict(fit,x_test)
7. K-Means
É um tipo de algoritmo sem supervisão que resolve problemas de agrupamento. O seu procedimento segue uma maneira simples e fácil para classificar um dado conjunto através de um certo número de grupos de dados (assumir k clusters). Os pontos de dados dentro de um cluster são homogêneas e heterogêneas para grupos de pares.
Lembra de como descobrir formas de borrões de tinta? k é um pouco semelhante esta atividade. Você olha para a forma que se espalhou para decifrar quantos diferentes clusters / população estão presentes!

Como K-means faz os clusters:
- K-means pega número k de pontos para cada grupo conhecido como centróide.
- Cada ponto de dados forma um cluster com o centróide mais próximo, i.e. k aglomerados.
- Encontra-se o centróide de cada cluster com base em membros do cluster existente. Aqui temos novos centróides.
- Em tendo novos centróides, repita o passo 2 e 3. Encontre a distância mais próxima para cada ponto de dados a partir de novos centróides e os associe com as novas-k clusters. Repita este processo até que a convergência ocorra, isto é, os centróides não mudem.
Como determinar o valor de K:
Em K-means, temos grupos e cada grupo tem seu próprio centróide. A soma dos quadrados da diferença entre centróides e os pontos de dados dentro de um cluster constitui-se da soma do valor quadrado para esse cluster. Além disso, quando a soma dos valores quadrados para todos os clusters são adicionados, ela se torna o total dentro soma do valor quadrado para a solução de cluster.
Sabemos que, com o aumento no número de clusters, este valor continua diminuindo, mas se você traçar o resultado você pode ver que a soma das distâncias ao quadrado diminui acentuadamente até algum valor de k e, em seguida, muito mais lentamente depois disso. Aqui, podemos encontrar o número ideal de clusters.

Código Python
#Importa a biblioteca from sklearn.cluster import KMeans #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria modelo de objeto de classificação KNeighbors k_means = KMeans(n_clusters=3, random_state=0) #Treina o modelo usando os dados de treino e confere o score model.fit(X) #Prevê o resultado predicted= model.predict(x_test)
Código R
library(cluster)
fit <- kmeans(X, 3) # 5 cluster solution
8. Floresta Aleatória
Floresta aleatória é um termo sinônimo a conjunto de árvores de decisão. Na Floresta Aleatória, temos uma coleção de árvores de decisão (assim conhecido como “Floresta”). Para classificar um novo objeto com base em atributos, cada árvore dá uma classificação e dizemos que a árvore “vote” para essa classe. A floresta escolhe a classificação que tenha a maioria dos votos (mais que todas as árvores da floresta).
Cada árvore é plantada e cultivada como se segue:
- Se o número de casos no conjunto de treinamento é N, então a amostra de casos de n é tomado aleatoriamente mas com substituição. Esta amostra será o conjunto de treinamento para o cultivo da árvore.
- Se existem M variáveis de entrada, um número m < M é especificado de modo que a cada nó, as variáveis m sejam selecionadas aleatoriamente para fora do M e a melhor divisão sobre estes m é usado para dividir o nó. O valor de m é mantido constante durante o crescimento da floresta.
- Cada árvore é cultivada na maior extensão possível. Não há poda.
Para mais detalhes sobre esse algoritmo, comparando com os parâmetros da árvore de decisão e modelo tuning, eu sugiro que você leia estes artigos:
- Introdução à floresta Aleatório – Simplificado
- Comparando um modelo de carrinho para a Random Floresta (Parte 1)
- Comparando a Floresta Aleatória a um modelo CART (Parte 2)
- Ajustando os parâmetros do seu modelo Floresta Aleatória
Código Python
#Importa a biblioteca from sklearn.ensemble import RandomForestClassifier #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria objeto Random Forest model= RandomForestClassifier() #Treina o modelo usando os dados de treino e confere o score model.fit(X, y) #Prevê o resultado predicted= model.predict(x_test)
Código R
library(randomForest) x <- cbind(x_train,y_train) #Modelo de acerto fit <- randomForest(Species ~ ., x,ntree=500) summary(fit) #Prevê o resultado predicted= predict(fit,x_test)
9. Algoritmo de Redução de Dimensionalidade
Nos últimos 4 a 5 anos, tem havido um aumento exponencial na captura de dados. Corporações, agências governamentais e organizações de pesquisa não apenas têm novas fontes de dados, mas também estão capturando dados em grandes detalhes.
Por exemplo: empresas de comércio eletrônico estão capturando mais detalhes sobre o cliente como sua demografia, rastreando sua história na web, o que eles gostam ou não gostam, histórico de compras, feedback e muitas outras informações para dar-lhes atenção personalizada e maior do que o lojista de supermercado mais próximo.
Como um data scientist, os dados que são oferecidos também consistem em muitas características, isso soa bem para a construção de modelos robustos, mas existe um desafio. Como identificar variáveis altamente significativas entre 1000 ou 2000 delas? Em tais casos, o algoritmo de redução de dimensionalidade nos ajuda, juntamente com vários outros algoritmos como árvore de decisão, Floresta Aleatória, PCA, análise fatorial, Identificação baseada em matriz de correlação, relação de valor e outros.
Para saber mais sobre este algoritmos, você pode ler “Beginners Guide To Learn Dimension Reduction Techniques“.
Código Python
#Importa a biblioteca from sklearn import decomposition #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria objeto PCA pca= decomposition.PCA(n_components=k) #valor de default de k = min(n_sample, n_features) #Fará análise de fator fa = decomposition.FactorAnalysis() #Reduz a dimensão dos dados de treino usando PCA train_reduced = pca.fit_transform(train) #Reduz a dimensão dos dados de teste test_reduced = pca.transform(test) #Para maiores detalhes, veja esse link.
Código R
library(stats) pca <- princomp(train, cor = TRUE) train_reduced <- predict(pca,train) test_reduced <- predict(pca,test)
10. Gradient Boosting & AdaBoost
10.1 GBM
GBM & AdaBoost estão impulsionando algoritmos usados quando lidamos com uma grande quantidade de dados para fazer uma previsão com alto poder. O reforço é um algoritmo de aprendizagem conjunto que combina a previsão de vários estimadores de base para melhorar a robustez em relação a um único estimador. Ele combina vários preditores fracos ou médios a um preditor forte de construção. Esses algoritmos sempre funcionam bem em competições de ciência de dados, como Kaggle, AV Hackathon, CrowdAnalytix.
Mais: Know about Gradient and AdaBoost in detail
Código Python
#Importa a biblioteca from sklearn.ensemble import GradientBoostingClassifier #Assume que você tem X (previsor) e Y (alvo) para dados de treino e x_test(previsor) dos dados de teste #Cria o objeto Gradient Boosting Classifier model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0) #Treina o modelo usando os dados de treino e confere o score model.fit(X, y) #Prevê o resultado predicted= model.predict(x_test)
Código R
library(caret) x <- cbind(x_train,y_train) #Modelo de acerto fitControl <- trainControl( method = "repeatedcv", number = 4, repeats = 4) fit <- train(y ~ ., data = x, method = "gbm", trControl = fitControl,verbose = FALSE) predicted= predict(fit,x_test,type= "prob")[,2]
GradientBoostingClassifier e Floresta Aleatória são dois classificadores de árvore diferentes e muitas vezes as pessoas perguntam sobre a diferença entre estes dois algoritmos.
10.2 XGBoost
Outro algoritmo clássico de ‘boosting’ de gradiente, conhecido por ser a escolha decisiva entre ganhar ou perder em algumas competições de Kaggle.
O XGBoost possui um poder preditivo imensamente alto que o torna a melhor escolha para precisão em eventos, pois possui tanto o modelo linear quanto o algoritmo de aprendizado de árvores, tornando o algoritmo quase 10x mais rápido do que as técnicas existentes de ‘boosting’ de gradiente.
O suporte inclui várias funções objetivas, incluindo regressão, classificação e classificação.
Uma das coisas mais interessantes sobre o XGBoost é que ele também é chamado de técnica de reforço regularizado. Isso ajuda a reduzir a modelagem de overfit e tem um suporte massivo para várias linguagens, como Scala, Java, R, Python, Julia e C ++.
Suporta treinamento distribuído e difundido em muitas máquinas que abrangem clusters GCE, AWS, Azure e Yarn. O XGBoost também pode ser integrado com o Spark, o Flink e outros sistemas de fluxo de dados em nuvem com uma validação cruzada incorporada em cada iteração do processo de aprimoramento.
Para saber mais sobre o XGBoost e o ajuste de parâmetros, visite “Complete guide parameter tunind xgboost with coeds python“.
Código Python
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X = dataset[:,0:10]
Y = dataset[:,10:]
seed = 1
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=seed)
model = XGBClassifier()
model.fit(X_train, y_train)
#Fazer previsões para os dados de treino
y_pred = model.predict(X_test)
Código R
require(caret)
x <- cbind(x_train,y_train)
# Modelo de ajuste
TrainControl <- trainControl( method = "repeatedcv", number = 10, repeats = 4)
model<- train(y ~ ., data = x, method = "xgbLinear", trControl = TrainControl,verbose = FALSE)
OR
model<- train(y ~ ., data = x, method = "xgbTree", trControl = TrainControl,verbose = FALSE)
predicted <- predict(model, x_test)
10.3 LightGBM
O LightGBM é um framework de aprimoramento de gradiente que usa algoritmos de aprendizado baseados em árvore. Ele é projetado para ser distribuído e eficiente, tendo as seguintes vantagens:
- Velocidade de treinamento mais rápida e maior eficiência
- Menor uso de memória
- Melhor precisão
- Suporte a aprendizado em paralelo e em GPU
- Capaz de lidar com dados em grande escala
O framework é um gradiente rápido e de alto desempenho baseado em algoritmos de árvore de decisão, usados para ranqueamento, classificação e muitas outras tarefas de machine learning. Foi desenvolvido no âmbito do projeto “Distributed Machine Learning Toolkit” da Microsoft.
Como o LightGBM é baseado em algoritmos de árvore de decisão, ele divide a folha de árvore com o melhor ajuste, enquanto outros algoritmos de divisão dividem a árvore por profundidade ou por níveis, ao invés de folhas. Assim, quando crescendo na mesma folha no GBM Light, o algoritmo por folha pode reduzir mais as perdas do que o algoritmo por nível e, portanto, resultar em uma precisão muito melhor que raramente pode ser alcançada por qualquer dos algoritmos de boost existentes.
Além disso, é surpreendentemente muito rápido, daí a palavra “Light” (ie, leve).
Consulte o artigo para saber mais sobre o LightGBM: Which algorithm takes the crown.
Código Python
data = np.random.rand(500, 10) # 500 entidades, cada contém 10 elementos label = np.random.randint(2, size=500) # alvo binário train_data = lgb.Dataset(data, label=label) test_data = train_data.create_valid('test.svm') param = {'num_leaves':31, 'num_trees':100, 'objective':'binary'} param['metric'] = 'auc' num_round = 10 bst = lgb.train(param, train_data, num_round, valid_sets=[test_data]) bst.save_model('model.txt') # 7 entidades, cada contém 10 elementos data = np.random.rand(7, 10) ypred = bst.predict(data)
Código R
library(RLightGBM) data(example.binary) #Parâmetros num_iterations <- 100 config <- list(objective = "binary", metric="binary_logloss,auc", learning_rate = 0.1, num_leaves = 63, tree_learner = "serial", feature_fraction = 0.8, bagging_freq = 5, bagging_fraction = 0.8, min_data_in_leaf = 50, min_sum_hessian_in_leaf = 5.0) #Cria o handle e o booster de dados handle.data <- lgbm.data.create(x) lgbm.data.setField(handle.data, "label", y) handle.booster <- lgbm.booster.create(handle.data, lapply(config, as.character)) #Treino para num_iterations iterações e avalia a cada 5 passos lgbm.booster.train(handle.booster, num_iterations, 5) #Prevê pred <- lgbm.booster.predict(handle.booster, x.test) #Testa precisão sum(y.test == (y.pred > 0.5)) / length(y.test) #Salva o modelo (pode ser aberto via lgbm.booster.load(filename)) lgbm.booster.save(handle.booster, filename = "/tmp/model.txt")
Se você estiver familiarizado com o pacote Caret em R, esse é outro jeito de implementar o LightCBM
require(caret)
require(RLightGBM)
data(iris)
model <-caretModel.LGBM()
fit <- train(Species ~ ., data = iris, method=model, verbosity = 0)
print(fit)
y.pred <- predict(fit, iris[,1:4])
library(Matrix)
model.sparse <- caretModel.LGBM.sparse()
#Gera a matriz sparse
mat <- Matrix(as.matrix(iris[,1:4]), sparse = T)
fit <- train(data.frame(idx = 1:nrow(iris)), iris$Species, method = model.sparse, matrix = mat, verbosity = 0)
print(fit)
10.4 Catboost
O CatBoost é um algoritmo de machine learning recentemente aberto pela Yandex. Ele pode se integrar facilmente a estruturas de deep learning como o TensorFlow do Google e o Core ML da Apple.
A melhor parte do CatBoost é que ele não exige treinamento extensivo de dados como outros modelos ML, e pode funcionar em uma variedade de formatos de dados, não diminuindo o quão robusto pode ser.
Certifique-se de tratar os valores faltantes antes de prosseguir com a implementação.
O Catboost pode lidar automaticamente com variáveis categóricas sem mostrar o erro de conversão de tipo, o que ajuda você a se concentrar em ajustar melhor seu modelo em vez de resolver erros triviais.
Saiba mais sobre o Catboost neste artigo: Catboost automated categorical data.
Código Python
import pandas as pd import numpy as np from catboost import CatBoostRegressor #Lê arquivos de treino e de teste train = pd.read_csv("train.csv") test = pd.read_csv("test.csv") #Insere valores faltantes para ambos treino e teste train.fillna(-999, inplace=True) test.fillna(-999,inplace=True) #Cria um conjunto de treino para modelagem e conjunto de validação para checar performance do modelo X = train.drop(['Item_Outlet_Sales'], axis=1) y = train.Item_Outlet_Sales from sklearn.model_selection import train_test_split X_train, X_validation, y_train, y_validation = train_test_split(X, y, train_size=0.7, random_state=1234) categorical_features_indices = np.where(X.dtypes != np.float)[0] #Importa biblioteca e modelo de construção from catboost import CatBoostRegressormodel=CatBoostRegressor(iterations=50, depth=3, learning_rate=0.1, loss_function='RMSE') model.fit(X_train, y_train,cat_features=categorical_features_indices,eval_set=(X_validation, y_validation),plot=True) submission = pd.DataFrame() submission['Item_Identifier'] = test['Item_Identifier'] submission['Outlet_Identifier'] = test['Outlet_Identifier'] submission['Item_Outlet_Sales'] = model.predict(test)
Código R
set.seed(1)
require(titanic)
require(caret)
require(catboost)
tt <- titanic::titanic_train[complete.cases(titanic::titanic_train),]
data <- as.data.frame(as.matrix(tt), stringsAsFactors = TRUE)
drop_columns = c("PassengerId", "Survived", "Name", "Ticket", "Cabin")
x <- data[,!(names(data) %in% drop_columns)]y <- data[,c("Survived")]
fit_control <- trainControl(method = "cv", number = 4,classProbs = TRUE)
grid <- expand.grid(depth = c(4, 6, 8),learning_rate = 0.1,iterations = 100, l2_leaf_reg = 1e-3, rsm = 0.95, border_count = 64)
report <- train(x, as.factor(make.names(y)),method = catboost.caret,verbose = TRUE, preProc = NULL,tuneGrid = grid, trControl = fit_control)
print(report)
importance <- varImp(report, scale = FALSE)
print(importance)
Notas Finais
Tenho certeza que agora você tem uma ideia de algoritmos de machine learning comumente utilizados. Minha única intenção por trás deste artigo, e em fornecer os códigos em R e Python, é para você começar imediatamente. Se você estiver interessado em dominar machine learning, comece imediatamente. Pegue alguns problemas, desenvolva uma compreensão física do processo, aplique esses códigos e divirta-se!
Você achou este artigo útil? Compartilhar seus pontos de vista e opiniões na seção de comentários.
Veja também:
Cara, seu blog é muito bom. Parabéns!
Que bom que gostou, Elias
Volte sempre.
Excelente! Parabéns.
Tirou todas minhas duvidas, vlw
Many thanks a whole lot for sharing!
Simplesmente perfeito! Alguns algoritmos apresentados eu nem conhecia! muito bom mesmo!
De cara fui testando aqui em uns dados de estudo, e me assustou ver que Logistic Regression me trouxe resultados muito bons em uma classificação com nltk e cross_validation, consideravelmente melhor que outros 9 algortimos, levando em consideração já dados de validação 🙂
Cara, é isso que eu precisava! Muito bom mesmo, parabéns!
🙂
Material incrível !!!
Que riqueza de conteúdo! Lucido demais!!! Muito obrigado por compartilhar um conteúdo tão rico com a gente <3
Amigo, faz 5 dias que entrei nos estudos dessa área fascinante área.
Artigo objetivo, exposto de forma clara e ainda com exemplo de código.
Muito obrigado!
Muito bom, os códigos acompanhando as descrições ficaram ótimos, valeu!!
Saved as a favorite, I really like your blog!
Simplesmente fantástico!